1. Context and Objectives
This project implements a production-ready ETL pipeline for monitoring Instagram account followings with automated change detection, machine learning predictions, and comprehensive data quality tracking. The system runs 24/7 with complete autonomy once Docker Desktop is launched.
Key Objectives
- Automated Surveillance: Scrape Instagram followings every ~4 hours (6 times/day) with anti-detection strategies
- Change Detection: Identify new followings and unfollows through intelligent daily comparisons
- ML Predictions: Automatic gender prediction with confidence scores using machine learning
- Quality Tracking: Comprehensive quality score system tracking scraping completeness and accuracy
- Real-Time Dashboards: Modern web dashboard and Kibana visualizations with advanced filters
- Structured Data Lake: Three-layer architecture (RAW → FORMATTED → USAGE)
The main challenge was designing a robust system that balances data collection frequency, anti-detection mechanisms, and quality assurance while maintaining 24/7 autonomous operation.
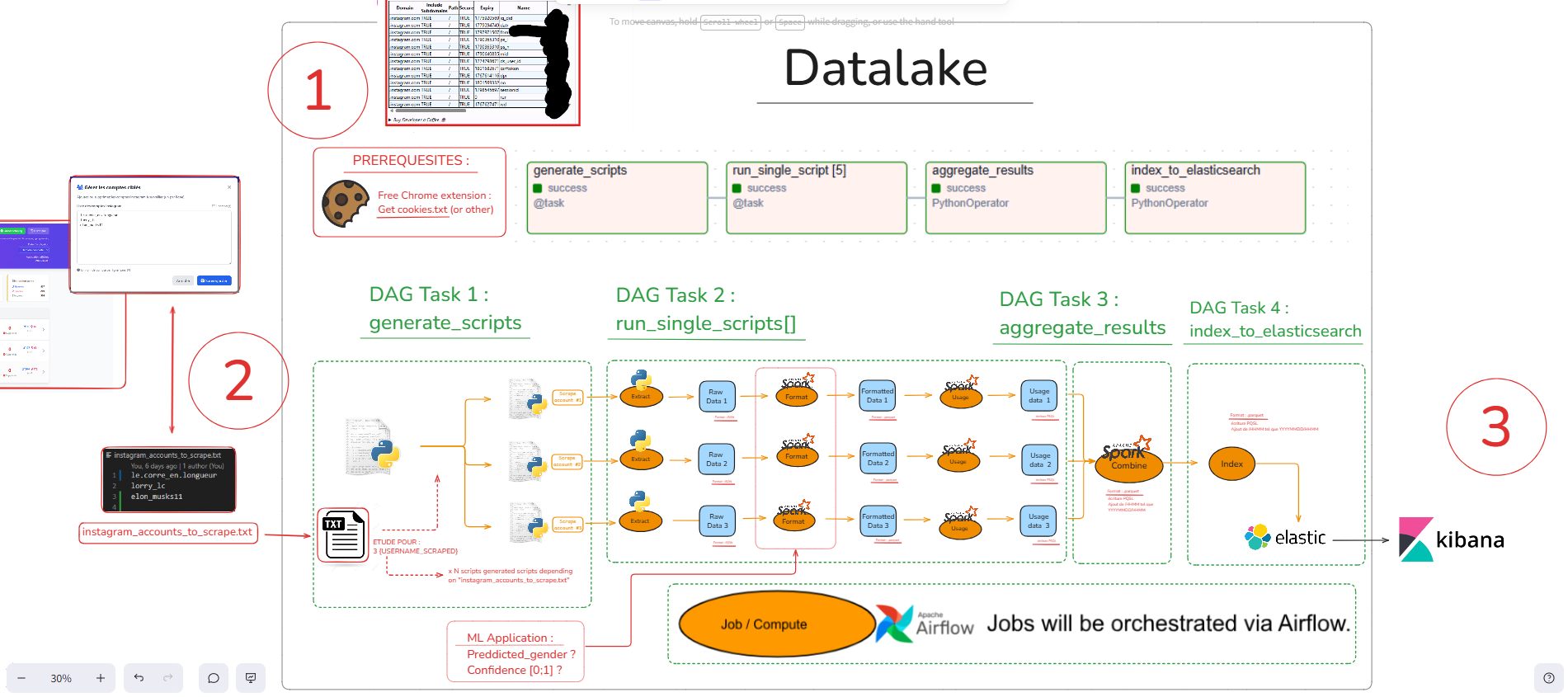
Figure 1 - High-level overview of the Instagram surveillance pipeline
Démo d'un run RAG (mode visuel activé via serveur X11)
⚠️ ATTENTION : LES DONNEES RECUPEREES NE RESPECTENT PAS LA RGPD ET CE PROJET A ETE REALISE DANS UN CADRE ACADEMIQUE UNIQUEMENT
2. System Architecture
The ETL pipeline follows a modular microservices architecture orchestrated by Apache Airflow with full Docker containerization.
Automated Execution Flow
The system executes on a precisely timed schedule (Europe/Paris timezone):
- 6 Daily Scrapings: 02:00, 06:00, 10:00, 14:00, 18:00, 23:00 (+ random delay 0-45min for anti-detection)
- 3 Passes Per Scraping: Multiple passes with 60-120s random delays to simulate human behavior
- Daily Aggregation: 23:00 - Fusion of all 6 daily scrapings with deduplication
- Daily Comparison: 23:00 - Detection of new followings and unfollows (Day vs Day-1)
Microservices Stack
Orchestration
- Apache Airflow 2.10.3
- LocalExecutor
- DAG Scheduler 24/7
Data Collection
- Selenium 4.36
- Chrome Headless
- Cookie Authentication
Processing
- PySpark 4.0.1
- Pandas
- Scikit-learn 1.6.0
Storage & Visualization
- PostgreSQL 14
- Elasticsearch 8.11
- Kibana 8.11
- Flask Dashboard
Data Lake Architecture
data/
├── raw/ # Raw JSON from scraping
│ └── YYYY-MM-DD_HH-MM-SS/
├── formatted/ # Cleaned data with ML predictions
│ └── YYYY-MM-DD_aggregated/
└── usage/ # Daily aggregations & comparisons
└── YYYY-MM-DD_comparatif/
Prérequis et guide d'installation
Prérequis
- Docker Desktop - Pour la conteneurisation de tous les services
- VS Code - Éditeur de code recommandé
- Extension Chrome "Cookies.txt" - Pour extraire les cookies d'authentification Instagram
- Compte Instagram personnel - Nécessaire pour l'authentification et le scraping
Étapes d'installation
git clone https://github.com/martin-lcr/Datalake_Instagram_Following_Surveillance.git
make install
make help → see all available commands
make status
3. ETL Pipeline Stages
Three-stage pipeline combining Selenium scraping, PySpark processing, and multi-target storage.
- Extraction: Selenium-based scraping with cookie auth, 3 passes, and rate limiting (60-120s delays)
- Transformation: PySpark processing with ML gender prediction, quality scoring, and daily aggregation
- Loading: PostgreSQL, Elasticsearch, and JSON data lake (RAW/FORMATTED/USAGE layers)
make open
Modifier la liste des comptes instagram surveillés
Lancement de la pipeline et trigger manuel du DAG pour demo
4. Quality Tracking System
Automated quality assurance with completeness scoring and intelligent comparison to eliminate false positives.
- Completeness Score: (scraped / total_instagram × 100) with HIGH/MEDIUM/LOW confidence levels
- Threshold Filtering: Configurable minimum (default 80%) to ignore incomplete scrapings
- False Positive Prevention: Only detects genuine changes, not artifacts from partial scrapings
Logs Airflow pour suivi détaillé du déroulement de chaque run
5. Anti-Detection Strategy
Comprehensive mechanisms to avoid Instagram rate limiting through timing strategies and behavioral simulation.
- Timing: 6×/day with irregular intervals (3-5h) and random delays (0-45 min)
- Behavior: 3 passes per scraping, 60-120s delays, persistent cookies, headless Chrome
- Risk Mitigation: Account limits, cookie rotation (1-3 months), graceful error handling
6. Docker Architecture
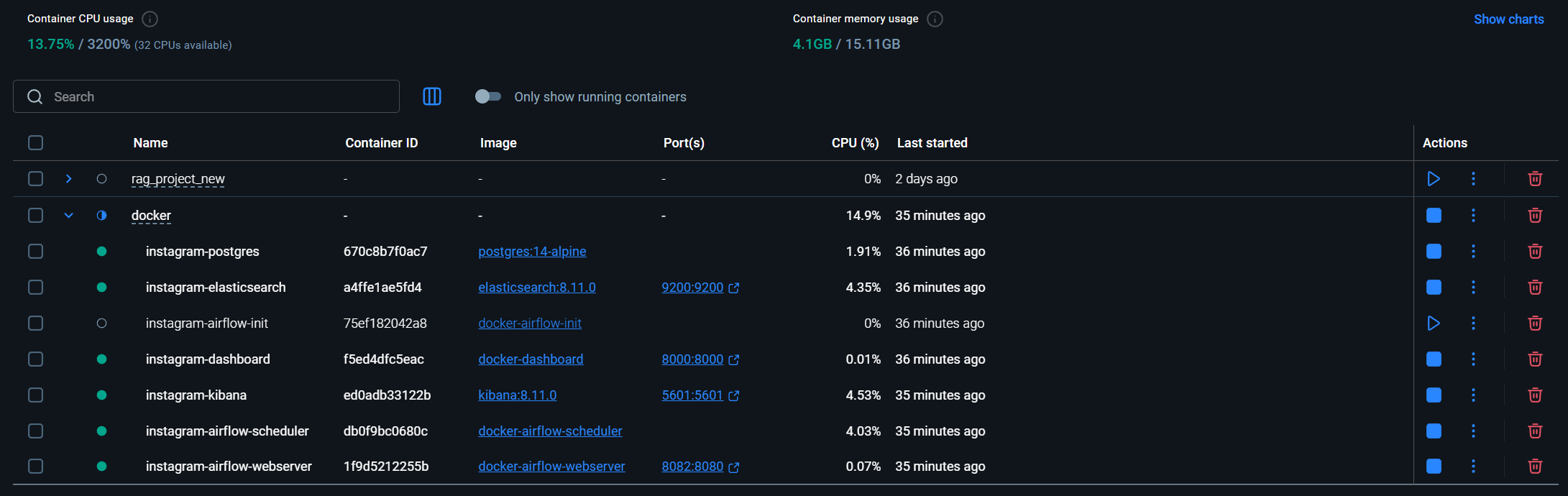
Figure 8 - Architecture de conteneurisation Docker avec tous les services
7. Technical Implementation
Docker containerization with Makefile automation and optional Oracle Cloud deployment.
- Docker: Full containerization with custom Airflow image, service isolation, persistent volumes
- Makefile: One-command install (5-7 min), start/stop, dashboard auto-open, cookie validation
- Cloud: Oracle Free Tier option (4 OCPU, 24 GB RAM, 200 GB storage)
8. Conclusion
This project demonstrates a production-ready ETL pipeline achieving 24/7 autonomous operation with robust quality tracking and effective anti-detection mechanisms. Multi-pass scraping significantly improves data completeness while Docker containerization enables seamless cloud deployment.
Future enhancements include advanced ML for profile analysis, real-time alerts, API development, and multi-platform extension.
Technologies & Resources
Key Technologies
- Apache Airflow: Workflow orchestration platform - https://airflow.apache.org/
- PySpark: Python API for Apache Spark - https://spark.apache.org/docs/latest/api/python/
- Selenium: Web browser automation - https://www.selenium.dev/
- Elasticsearch: Search and analytics engine - https://www.elastic.co/elasticsearch/
- Kibana: Data visualization and exploration - https://www.elastic.co/kibana/
Project Information
Status: Production-ready, running 24/7
Deployment: Docker containerization with Oracle Cloud support
Contact: For technical inquiries, contact Martin LE CORRE
Documentation: 📄 View detailed README
Legal Notice
This project is provided for educational and research purposes only. Use responsibly and in compliance with Instagram's Terms of Service and data protection laws (GDPR).